
Vous trouverez ci-dessous un compte-rendu du dixième chapitre intitulé “L’organisation des métadonnées” de Grégory Fabre et Sophie Marcotte, issu du livre Pratiques de l’édition numérique.
Afin de synthétiser j’ai fais le choix de structurer le compte rendu sous formes de questions/réponses et de résumer les caractéristiques des différents outils pour organiser les métadonnées.
Les métadonnées.
Les métadonnées qu’est-ce que c’est ?
Ce sont des informations, qui décrivent un contenu et également des tags, qui permettent de retrouver des données grâce à une ontologie commune.
A quoi servent les métadonnées ?
Elles permettent de caractériser et structurer des ressources numériques. Grâce à elles nous pouvons réaliser une taxinomie (classification) du monde, et faire circuler des connaissances. Notamment en facilitant la recherche d’information grâce à la description de contenu et leurs classes, avec le référencement. Les métadonnées facilitent également l’archivage et l’interopérabilité. Elles servent aussi à gérer des droits d’accès à des pages web, et encoder une signature électronique pour certifier et authentifier un contenu.
Quel est le but principal des métadonnées ?
Son but premier est de permettre aux machines d’exploiter automatiquement les contenus de sources d’information, accessibles par le Web, pour réaliser des tâches variées. La réalisation de cet objectif repose sur l’existence de données structurées. Par exemple elles participent à l’optimisation des moteurs de recherches grâce aux SEO (Search Engine Optimatization) , pour en quelques sortes indexer les sites web.
Les formats sémantiques
La structuration de données
Microformats ou entités servent à décrire de manière précise un contenu numériques qui possèdent des propriétés propres. Un événement sera défini par les propriétés « date », « lieu », « type d’événement », « heure », « contact ». Son utilisation est utilisée pour concevoir des annuaires.
Microdata permet de créer des liens sémantiques entre les contenus déjà présents sur le web en ajoutant des balises à la structure HTLM. C’est-à-dire qu’ils permettent aux moteurs de recherche de comprendre le contenu des pages grâce à une hiérarchisation et d’extraire les contenus microdata pour réaliser un référencement.
RDF (Ressource Description Framework) structure le contenu grâce à un ensemble de triplets: le sujet qui est la ressource à décrire, le prédicat qui est le type de propriété applicable au sujet et l’objet qui est la valeur de la propriété. Ce format doit être traduit par les agents logiciels qui échangent de l’information entre eux pour être utilisé.
OWL (Web Ontology Language) est un prolongement de RDF. Il s’agit d’un format qui permet de clarifier ce qui ne peut pas être compris d’emblée par la machine en fournissant un langage propice à l’élaboration d’une ontologie (l’étude de l’être).
FOAF (Friend of a Friend) est un vocabulaire qui repose sur du RDF et OWL, il permet de décrire des personnes et les corrélations qu’elles entretiennent entre elles ou avec des objets. Il permet aussi de crypter des adresses mails.
OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) est un mécanisme favorisant l’interopérabilité entre différentes sources de référence. C’est-à-dire qu’il détermine les conditions du transfert des métadonnées produites par un fournisseur de données, vers le serveur d’un fournisseur de services. Il permet d’échanger des métadonnées entre plusieurs institutions, accroître la visibilité des collections numériques sur Internet et d’indiquer des ressources non accessibles aux moteurs de recherche.
Dublin Core équivaut à une liste de métadonnées liées aux sites web. Il permet de normaliser les balises qui décrivent les références bibliographiques et d’établir des relations entre elles et d’autres ressources. Il comporte 15 propriétés balisés qui permettent de désigner communément l’agrégat de contenu de bases différentes.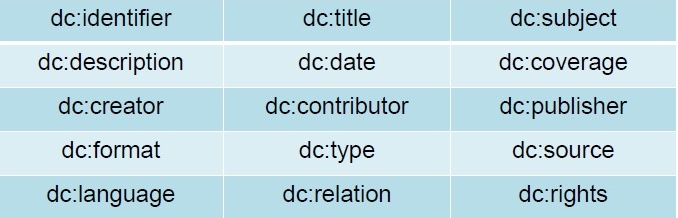
Drupal est un système de gestion de contenu (CMS) gratuit et Open Source c’est à dire accessible sans payer une licence et que tout le monde peut participer à son amélioration. Il permet de produire, gérer, et diffuser du contenu. Grâce à ce système de contenu les programmeurs évite les processus de saisi et de gestion des métadonnées.
SPARQL (Sparql Protocol and RDF Query Language) est un langage qui enregistre et fusionne les données qui viennent de sources différentes. Il permet de rechercher et gérer des données RDF.
Apache Solar permet de réaliser des recherches avancée au sein d’une base de données complexe grâce à son interface HTML et son filtrage de données. L’objectif est de pouvoir efficacement rechercher de manière transversale sur l’ensemble des sites.
TEI (Text Encoding Initiative) est employé avec les balises XML il sert à faciliter la création, l’échange, et l’intégration des données textuelles informatisées. Il permet de décrire la manière dont un document a été créé et structuré (lignes, chapitres, paragraphes, dialogues, ratures…). Accompagné du RDF il permet de mettre en relation des sources. Il est surtout adopté pour des projets éditoriaux anciens, de manuscrits et permet de reconstituer le processus menant à la version définitive d’un texte.
L’organisation des métadonnées peut être complexe, c’est pour cela qu’il est nécessaire de connaître les différents formats proposés et les langages utiles pour répondre aux différents besoins. Besoins qui peuvent être professionnels, éditoriaux, scientifiques ou documentaires. Sachez que l’ELO (Electronic Literature Organization) a lancé le projet CELL (Consortium of Electronic Literature) afin de réunir les informations des bases de données réparties dans les laboratoires de recherche qui étudient la création et l’étude des hypermédias. Il permettra à terme la normalisation et la densification de données partagées.
Justine,
Cette approche de questions/réponses est bien choisie.
J’y avais également pensé pour la réalisation de mes articles.
Je trouve que cela permet aux lecteurs de comprendre rapidement le coeur du sujet.
C’est gentil, j’espère avoir réussi à t’éclairer sur l’organisation des métadonnées.
J’ai hâte de lire ton article 🙂